
October 8, 2025 by Yotta Labs
Why Autoscaling Breaks Down for Latency-Sensitive Workloads
Autoscaling works well for predictable, batch-oriented workloads. For latency-sensitive LLM inference, it often does the opposite. Cold starts, batching disruption, and cache churn mean scaling events frequently increase tail latency and reduce GPU utilization precisely when systems are under the most pressure. Understanding why autoscaling breaks down in inference requires looking at real runtime behavior, not just scaling theory.

Autoscaling is one of the first mechanisms teams adopt when they start running LLM inference in production. The idea is straightforward: scale up when traffic spikes, scale down when it falls, and let the system absorb variability automatically.
For many stateless and batch-oriented workloads, this works well. For latency-sensitive LLM inference, it often fails.
In practice, autoscaling frequently increases tail latency, destabilizes batching behavior, and reduces effective GPU utilization—precisely during periods of peak demand.. Understanding why requires examining how inference behaves under real traffic, not just how autoscaling works in theory.
Why Autoscaling Works for Training but Struggles with Inference
Autoscaling was originally designed for workloads with predictable execution patterns. Taking training as the example. Training workloads are internally scheduled. Jobs are long-lived, predictable, and tolerant of queueing. Spinning up a new GPU or node is a one-time cost that gets amortized over hours or days of compute.
Inference is the opposite.
Inference workloads are externally driven by user traffic. Requests arrive unevenly, carry latency expectations, and vary widely in size and duration. The system has no control over when work shows up, only how it reacts once it does.
This difference fundamentally alters how autoscaling behaves.
Cold Starts Are Not Free at Inference Time
When autoscaling provisions new capacity, that capacity is not immediately useful. For LLM inference, a new replica typically needs to:
- Launch a container or VM
- Load multi-GB model weights into GPU memory
- Initialize runtime and kernels
- Warm up execution paths
Even in optimized environments, this process commonly takes tens of seconds to several minutes, depending on model size and deployment architecture. During that window, incoming traffic continues to arrive. Latency does not improve until the new capacity is fully online, and in many cases, it temporarily worsens as requests queue up. Autoscaling reacts after the system is already under stress. It is a corrective mechanism, not a preventive one.
Scaling Events Disrupt Batching and Utilization
High-throughput inference depends heavily on batching. Autoscaling destabilizes batching at multiple levels.. When replicas are added or removed:
- Traffic gets redistributed
- Batch sizes changed temporarily and load becomes uneven
- Warm replicas lose steady request flow
- Cold replicas receive sporadic requests
The result is a short-term drop in batching efficiency across the fleet. Even though total GPU capacity increases, effective throughput per GPU decreases during scale events. This is why systems often see lower utilization immediately after scaling up, not higher.
Observed Behavior in Production Systems
In latency-sensitive inference systems, autoscaling behavior tends to follow a consistent pattern. Typical observations:
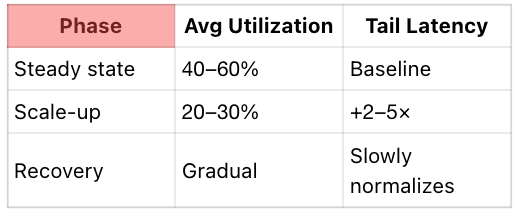
Average GPU utilization in steady state may sit around 40–60% when traffic is predictable. Under bursty traffic with autoscaling enabled, it is common to see utilization dip into the 20–30% range during scale-up and scale-down cycles. At the same time, tail latency often spikes by 2–5× relative to steady state while new replicas warm up and batching efficiency recovers. The net effect is counterintuitive: more GPUs online, higher latency, and worse cost efficiency during the moments when the system is under the most pressure. While directional, these ranges match what teams repeatedly observe in real deployments.
Autoscaling Encourages Overprovisioning by Another Name
Because autoscaling reacts too slowly for strict latency SLAs, teams often compensate by:
- Setting low scale-up thresholds
- Choosing large min-replica counts
- Keeping large buffers of idle capacity
- Avoiding scale-to-zero entirely
At that point, autoscaling is no longer reducing cost. It is simply masking overprovisioning behind dynamic rules. From a cost perspective, the system behaves much like a statically overprovisioned deployment, but with additional complexity and instability layered on top.
Memory and KV Cache Undermine Replica Interchangeability
Autoscaling assumes that replicas are interchangeable. Inference systems violate this assumption KV cache and memory state are local to each replica. When traffic shifts during scaling events, cache locality is lost. New replicas start with empty caches, while existing replicas may be memory-constrained. This further limits batching and concurrency exactly when demand is highest. Autoscaling increases capacity, but memory behavior prevents that capacity from being used efficiently.
Why “Scale Faster” Rarely Solves the Problem
It’s tempting to assume that faster scaling would solve the problem. In practice, there are hard limits:
- Model load time
- GPU initialization
- Storage I/O throughput
- Network congestion
- Runtime warm-up
Even with near-instant infrastructure provisioning, batching disruption and cache effects would remain. Autoscaling solves capacity, not coordination across dynamically allocated GPUs. Inference failures during spikes are usually orchestration failures, not hardware shortages.
The More Useful Question to Ask
Instead of asking:Why isn’t autoscaling keeping up?High-performing teams ask:How much stable capacity do we need to absorb traffic variability without frequent scaling ?
That question shifts the focus to:
- Baseline capacity sizing
- Traffic smoothing
- Admission control
- Replica placement and locality
- Churn minimization in the serving layer
Those factors determine whether autoscaling helps or hurts.
Closing Thoughts
Autoscaling is a powerful tool, but it was not designed for tight-latency, stateful inference workloads. For LLM inference, scaling events are often the most expensive and least efficient moments in the system lifecycle. Teams that rely heavily on autoscaling tend to trade predictable cost for unpredictable performance. The most reliable inference systems minimize scaling events rather than depend on them. They treat stable capacity and orchestration as first-class concerns, and use autoscaling sparingly, not as a primary control loop.
Further reading
- NVIDIA CUDA Programming Guide (execution and memory model)
- vLLM runtime architecture documentation
- Kubernetes autoscaling documentation (HPA/VPA limitations)